Real Time Science
April 27, 2025 | Hiya Jain & Samarth Jajoo
In 1869, alone in a damp kitchen of an old castle in Germany, Friedrich Miescher spent months looking into the components of pus cells, and coincidentally ended up isolating a new substance from their nuclei. We would eventually come to know of this material as DNA, but the true magnitude of the discovery somewhat evaded the young researcher. Although Miescher hypothesized that it could play a role in the generation of new life, he wrote up his findings as a simple biochemical observation: unusual, but not urgent.

His protocol was published two years later in dense German scientific prose with a title that translates to “On the Chemical Composition of Pus Cells” – hardly anything to be excited about. True to its name, the paper was mainly a methodological explanation for extracting the many components of white-blood cells. In fact, Miescher’s deliberation on the discovery of the DNA molecule goes but a little beyond calling it “nuclein” and noting its unusually high phosphorus content alongside its distinctiveness from proteins and fats. Unsurprisingly, the paper generated little immediate interest and was seen as yet another biochemical characterization among many of that era.1
What is truly interesting however, are the notes that were never published. He speculated in letters and notebooks that this molecule might be central to both reproduction and proliferation.2 His mentor Felix Hoppe-Seyler, however, insisted on repeating every experiment before allowing any publication and was sceptical of broader theorising, delaying Miescher’s original 1871 paper and leaving his bolder hypotheses confined to private correspondence. Regardless, he soon left his makeshift “lab” to train under another scientist before accepting a professorship where his research veered in a different direction, not returning to the question of ‘nuclein’ for several years3.
Had Miescher’s insights about nuclein’s role in reproduction been more widely recognized or had he pursued them more aggressively, the trajectory of biological science may have been dramatically different. The foundations of molecular genetics could have been established earlier. Instead, it would be almost eight decades until Oswald Avery, Colin MacLeod, and Maclyn McCarty conclusively demonstrated in 1944 that this material, Meischer’s ‘nuclein’, and not a protein as many had assumed, was indeed responsible for heredity – finally launching the decade-long endeavor to understand the structure of DNA.4
This story is a good example to get us thinking about science as a sprawling tree where each discovery opens up new branches to explore. Researchers start at the roots, and keep going until they find themselves at their chosen leaf on the frontier — but the intermediate nodes, which sometimes were truly at the cutting edge themselves, will often not be published. This pattern of scientific discovery, neglect, and rediscovery is more common than we would like to think.
Moreover, scientific stagnation stems not only from the loss of fundamental insights like Miescher's, but also from the disappearance of incremental and procedural knowledge that never makes it into formal publication. Because for every ten experiments, perhaps one ends up in the final paper. The rest – the intermediate steps, the ambiguous results, the dead ends, the subtle effects that didn’t replicate – remain tucked away in lab notebooks or forgotten entirely. Crucial technical ideas: better ways to calibrate an instrument, a trick to reduce noise in measurements, modifications to a protocol that saves hours, all become tacit knowledge. They are immensely valuable in getting things to work but are rarely written up, remaining hidden to everyone save the scientist themselves.5
Therefore, the story of scientific development tends to get lost and this is true even for publications describing incredibly exciting discoveries. Science can be messy but papers present a polished narrative where one logical step precedes the next and every key result can be summarised in a neat figure. In this framework miscellaneous experiments are pushed-out, sometimes to the appendix, and often from the paper entirely, for the sake of tidying up the manuscript.
In many respects, for scientists, choosing to go to graduate school is a sacrifice: a large opportunity cost paid in time and money that is mediated only by genuine curiosity. Upon entering the system however, even the best scientists are faced with a tough dilemma where working on the most ambitious projects comes with the risk of spending years being labeled ‘unproductive’ (i.e. not publishing).
While everyone values high-risk, high-reward science in principle, the practical reality is that researchers who take big risks need to consider the potential impact on their careers if those risks don't yield results.
Consider the plight of a newly enrolled graduate student: they might realistically be able to tackle about three substantial projects during their PhD. For an average scientist, each ambitious project might have only a 3% chance of yielding publishable results. Even if our researcher in this scenario is exceptionally talented and can boost those odds to 15% per project (or in other words is 5x better), the limited ability to sample gives them about a 61% chance8 of none of their projects resulting in a published manuscript (assuming they have the ability to take 3 of these bets during their PhD). It then becomes plausible that despite the scientist’s potential brilliance, they might have nothing tangible to showcase when they graduate, effectively shutting the door on their future scientific career. This is a devastating outcome for someone who chose this path out of genuine curiosity, passion, and ambition.
Clearly, this scenario is worth mitigating and so, there is a need to be pragmatic — finding a middle ground of ideas which are more easily possible, yet still exciting. We get a lot of good science this way: even incremental progress will often compound to solid expansions to the frontier. However, this system of publishing does create a self-perpetuating cycle of bad incentives, opaque science, and unhappy researchers.
This cycle of exchanging big ideas for stable careers is not new to American science. David Kaiser, for example, describes how the physicists who were once seen as solitary thinkers and tinkerers, got swept into the ‘suburbanization’ of the Cold War university system. Their departments ballooned and they ended up “trading cafes for cafeterias.”6 Graduate students arrived in waves, not to pursue wild ideas but to train for steady jobs to meet the increasing demands of industry or government research. The result was a more professional, productive, and well-funded science – and also one that could be read as a shift towards what Gerald Holton calls an “S2 system”: public, institutional science grounded in shared standards of empirical verification and logical rigor. What it displaced in some ways was “S1 science”: the private, intuitive domain that is often anchored in a sense of beauty and individual calling. As physicists themselves noted at the time, something got lost in the shift – a little curiosity, risk, and perhaps even the motive to do science in the first place.
We should consider different ways to measure scientific productivity and think about how we can change our metric from the number of prestigious publications to creating the largest “surface-area of shared information.” By incentivizing the documentation and publishing of failures and explorations of the intermediate leaves in scientific trees, we not only increase our collective understanding, but encourage graduate students to pursue their most ambitious ideas in a conducive environment.
In 2009, Fields Medalist Tim Gowers decided to attack a complex open problem in mathematics entirely in public. He wrote a blog post outlining his approach and invited anyone online to contribute. What followed is known today as the Polymath Project, a real-time experiment in massively collaborative problem solving. Over a few intense weeks, over a hundred comments were posted, and ideas were proposed, revised, discarded, and synthesized – often within hours. The end result was that a true solution emerged remarkably quickly and Gowers later described the experience as “to normal research [what] driving is to pushing a car.”
The project also surfaced a key idea that there is latent ‘micro-expertise’ scattered across the scientific world.7 This refers to people who, in narrow contexts, might have precisely the insight needed to move a problem forward and online tools enable this expertise to be activated in ways that conventional publishing or lab structures cannot. Leveraging micro-expertise also allows collaboration to benefit from probabilistic advantage – with more minds working on a problem, there is a greater chance that someone will have the specific perspective needed for a breakthrough.
In short, the Polymath Project reimagined what academic collaboration could look like: open, fast, chaotic, and remarkably effective. Importantly, it succeeded where others stalled because it combined open participation with just enough structure – clear ground rules, active moderation, and visible leadership – that kept momentum high. This mechanism was abundantly visible when the project tackled the Density Hales-Jewett problem, which exemplified what Gowers might have considered the “middle ground”: a problem significant enough to be challenging yet structured in a way that allowed multiple mathematicians to contribute different insights and approaches simultaneously.
However, Gowers himself raised a critical caveat on how far this model could generalize: could problems that “do not naturally split up into a vast number of subtasks” be effectively tackled by more than just a handful of people? In essence, the large-scale structure of Polymath makes it less effective for problems requiring a single transformative insight or those needing months of private contemplation to develop what mathematicians often call “mathematical intuition” – that pre-theoretical sense of a concept that precedes formal articulation. While the Polymath Project effectively amplified certain types of expert attention through parallelization, it struggled to cultivate the deep, sustained rumination that drives conceptual revolutions.
These limitations of Polymath reveal that different collaboration infrastructures might be needed for different types of intellectual activities. A compelling parallel here is Github, a platform that has transformed how large-scale software development happens by making previously invisible work processes completely transparent. On GitHub, the entire lifecycle of software development unfolds in public view: feature proposals through issues, implementation attempts via pull requests, the evolution of source code across versions, and the discussions that shaped critical decisions.
A developer might spot a bug and open an issue describing the problem. That report prompts others to investigate and suggest fixes. Then, if someone proposes a solution, they can share it through a pull request to invite open review and feedback before it is integrated. This process creates a massive, searchable repository of problem-solving: for almost any technical challenge, one can find discussions of failed approaches, successful implementations, and the reasoning behind design decisions. The platform therefore is not just an archive of final products but preserves the complete archaeology of how solutions evolved, with collaborations sometimes scaling to thousands of contributors.
Taken together, what both these examples demonstrate is that when the structure is right, collaboration can not only be broader but smarter – allowing expertise to find the problems it is best suited to solve. Michael Nielsen articulates this idea in his analysis of online scientific collaboration where he points out that expert attention is the ultimate scarce resource in scientific progress. Nielsen also writes about “restructuring expert attention”: the bottleneck is often the cognitive bandwidth of those with the specialized knowledge to interpret, connect, and advance ideas at the frontier.
This is where the true promise of both Polymath and GitHub-like systems lies: in their ability to create “attention markets” that operate with lower friction. These markets function by making problems and potential solutions visible to a wider audience and creating mechanisms for efficiently matching expertise to challenges. When Terence Tao posts a mathematical insight on his blog or when a developer submits a clever issue with a thorough spec, they are making a bid for expert attention in a more direct, immediate way than traditional channels allow.
Despite the general absence of public, collaborative infrastructure, scientists do have private mechanisms to document years of ideas, experiments, and iterations. The most ubiquitous of these is the lab notebook which has been a long held tradition where the researcher chronicles, with immense granularity, the true lives of scientific ideas. Within this journal one finds snapshots of quiet triumphs written down with as much sincerity as moments of failure and reflection. Thus, one can witness the false starts and gradual refinements that lead to illuminations at the frontier.

These notebooks really do have it all: photos of gels, observations, screenshots of analysis outputs, next steps. Unfortunately, the notes are typically trapped in isolated systems – bound notebooks, private Slack channels, or emails between collaborators. What we need instead are open, real-time, lab notebooks.
Think about a biologist, Dave, as he optimizes a PCR protocol for his single-cell atlas project. Dave writes down the settings, the samples, maybe takes a photo of the setup. Maybe he runs into an issue, and documents the troubleshooting steps he took, along with changes to the protocol. All of this is probably sitting in his lab notebook in Iowa City right now. But if it were in a shared, searchable system, it could help hundreds of other researchers dealing with similar setups. It is important to highlight that there is no extra work for Dave, except simply uploading his notes — and that being public does not imply being participatory9 — to interact further is a separate choice.
Where this gets really powerful though is in the connections that could be built. Say a researcher in Boston, Julia, is now tweaking a statistical analysis technique for scRNAseq data that is very similar to Dave’s, and because the system understands the connection, Dave gets a same-day notification about the new entry in Julia’s lab notebook — instead of two years later when it appears as an appendix to the methods section. Or maybe, Julia is stuck on a calibration issue with a specific instrument, and the system connects her with another biologist, Alan, who documented solving the exact same problem three months ago. A language model can ingest updates, and we can build semantic search infrastructure to have a big impact on Dave, Julia, and Alan’s research.10
Just a couple of years ago, these frequent updates would generate data that became nearly impossible to search through. Today, we have seen that language model based tools can help us find relevant scientific literature. For example Future House, a SF based non-profit, recently launched PaperQA 2: a LLM powered agent that can search over a large chunk of all the scientific literature out there, and out-performs postdoc-level biology researchers on retrieving relevant information. Tools like PaperQA can become even more powerful when they have access to information that doesn’t even make it to the publication. Imagine a world in which a researcher posts experimental results, and after a quick NotebookQA run, gets a notification stating their results look pretty different than runs from their colleagues, prompting them to repeat and verify their experiments. These are the kind of improvements that can save weeks on end for scientists.
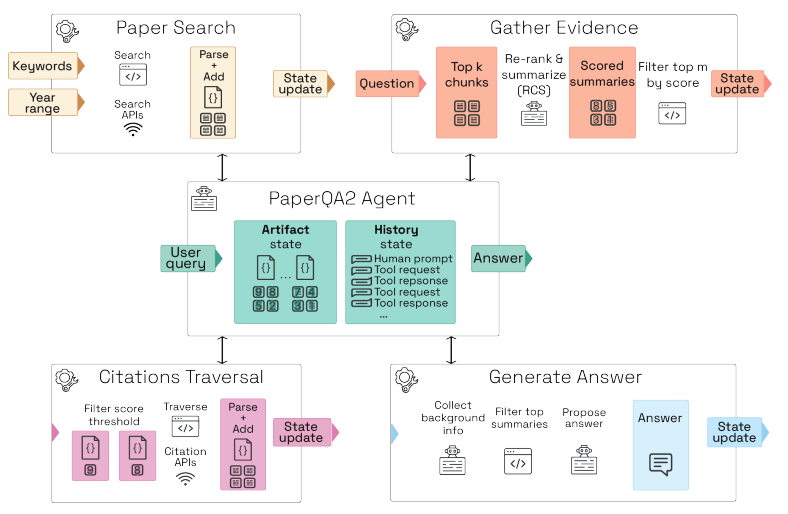
With the same infrastructure, we can create efficient attention markets where researchers (and perhaps even the public) can follow updates on scientific subfields. Instead of peer review happening on a manuscript or on the results of science, peers can provide feedback as the science progresses. They can point out potential issues in real-time, suggest controls that might have been missed, or offer alternative interpretations of the data. Researchers can incorporate this feedback and credit those who helped, or they can decide it is not relevant and move forward with their original approach. Either way, the entire exchange is visible and becomes part of the scientific record.
In this world, a project that fails to yield anything publishable would still create value by showing what approaches were tried and abandoned. The dead ends themselves become valuable signposts, and we appreciate the earnest scientists who really tried to work on crazy ideas instead of pointing to their lack of a publication record as reason to not hire them. Imagine a shared‑lab‑notebook ecosystem in which every branch climbed, every node explored, remains visible. A null result from an antibody that failed to bind or an organic synthesis that plateaued at sub-optimal yield all become tagged, timestamped reference points that future researchers can query. They stop someone in another lab, on another continent, from wasting three months repeating the same cul‑de‑sac, and they create a new, positive metric for the original scientist: the “surface-area of shared information” they contributed.
Review committees could count how many technically solid, substantial, but ultimately negative results someone contributed to the commons. Hiring panels would see evidence of ambitious swings rather than a thin CV filtered by the survivor bias of publishable results. Over time, whole subfields would acquire a “terrain map” of what has already been tried, encouraging bolder exploration because the personal cost of striking out drops dramatically. We can, and should, turn failure from a career liability into a public good.
This could also have a large impact on conventional funding pipelines, overhauling how resources are allocated. Currently, funding decisions are based on grant applications and publication records – lagging indicators that tell funders what someone has already done. But with science happening in the open, resources could flow dynamically to promising work as it emerges. A project showing unexpected results could attract additional funding, equipment access, collaborators, or computational resources, within weeks of the discovery, instead of two years later when the paper is published.
We think there are two core parts to making these open, real-time lab notebooks a reality: software and funding.
The process of doing research is chaotic, and the software should embrace that. Stream-of-consciousness notes, quick observations, voice memos — all fair game. No need for templated write-ups and rigid structure. The system should automatically extract key concepts and methods, making them discoverable without manual tagging. We have seen early versions of this idea: communities like OpenLabNotebooks tried to normalize transparency in day-to-day science. But the friction remains – logging entries still feels like a chore, and finding relevant past work is often harder than it should be. That is why it is crucial that the next iteration of these tools make it very easy to create, share and interact with notes. Well built software will make a huge difference here.
Ideally, this interface will also have a graduated approach to visibility for those who prefer updates being private, or shared with small groups to start with. We should aim to build software that is a value add for scientists even if they want to keep their findings close to their heart until they publish — essentially, a great blogging platform for research findings, even if the blogs are (semi) private.
If given permission, the software will make the daily work of science discoverable, and systematically create productive connections between researchers. It will surface these connections naturally, creating a map of scientific exploration that grows more valuable with each new entry. Like we showed earlier, this is tractable to build — and places like Future House and the Allen Institute have already been developing part of the stack which will enable it.
Meanwhile, funding is becoming a widespread and increasingly pressing issue with federal science budgets contracting as we are writing this. NSF director, Sethuraman Panchanathan, recently resigned from his post after facing calls to slash the agency’s budget for the coming year by 55%. The NIH is not faring any better: a Politico scoop details an internal proposal to slash the agency from 47 billion to 27 billion (around ‑40%) which comes alongside a push to consolidate its 27 institutes into just fifteen. This disruption in the traditional funding scheme creates challenges for the scientific enterprise at large, giving us an opportunity to experiment with how it operates: we think graduate students offer the perfect starting point for this transformation. They generate novel data daily, are actively building their scientific identity, and often most acutely feel the limitations of the current system.
A good way to kick-start the movement with some momentum would be to launch a fellowship program for them. Instead of piecing together funding through teaching and grant support, fellows would receive stable, flexible support to pursue their most interesting questions. At a time when federal science budgets are in retreat, this model would offer a timely and tractable way to sustain early-career researchers while piloting new norms for open, ambitious science. This financial and structural support creates the freedom to experiment not only with research ideas, but with how science itself gets done.
The fellowship’s mandate would be simple: work in public. Fellows share their journey – the data, the code, the half-formed hypotheses, the failed experiments. Not in a performative way, but as a natural extension of their research process. Instead of publication anxiety, fellows build a visible record of scientific contributions that go beyond the scope of traditional papers. The explorations themselves – not just the projects that make it into journals – become recognized as valuable scientific work.
Seeding the movement with an active core, and building a community around the process is essential to it taking off. This is, in some ways, a collective action problem, and the fellowship is a good way to counter academic pressures and competitive dynamics: things which could lead to the idea dying out before it is even tried out at any sort of scale.
Where the printing press gave rise to the scientific journal, the internet provides a similar opportunity to build something new entirely: something more dynamic and honest. We can capture the texture of research as it unfolds. And we now have the tools to make this possible, systems that render science searchable and collaborative.
If Miescher was a fellow working within such a paradigm, his early observations and speculations about ‘nuclein’ would not have remained hidden in letters and notebooks. Those insights, even as they were forming, would have been visible to others studying heredity – potentially accelerating one of biology’s most important discoveries by decades.
Scientists already recognize many of the problems that we have outlined here. The challenge is no longer awareness, but cultural imagination: how to shift the norms and incentives of science toward a new methodology. The current moment offers a rare alignment. On one hand, recent advances in software make this kind of infrastructure tractable, on the other, the instability of traditional funding has made the scientific community more open to rethinking how research is organized and supported. The friction is lower today than it has ever been — we just need to act.
With thanks to Jase Gehring, Eric Gilliam, Linus Lee, Neeraja Sankaran and Nim Tottenham for reading early drafts.
Additional Notes
- Erika DeAlden Benedictis has a series of posts which share project updates from her PhD: these updates are very well contextualised, and readable by non-biologists — they illustrate the kinds of information we want to collect.
- In 2007, Jean-Claude Bradley was already talking about open notebook science but the movement never really took off: information was scattered across different blogs and wikis, annoying to post, and hard to search through.
- Another reason for open notes is simply to make science less lonely. It is nice to have people following what you’re working on, and encouraging you when things look grim. A good example is how several makers follow each other on wip.co.
- It’s probably a bad idea to position the fellowship as an incentive to work in the open. We should find people who already want to (or already do) work in the open, and help them survive.